ECや不動産など多数の商材を扱うサイトにおいて、商品の情報を一括で抜き出したいと思うことはないでしょうか?
Googleスプレッドシートを使えば、URLの一覧から商品名や、価格情報などを一気に抽出することが出来ます。
それにはGoogleスプレッドシートのIMPORTXML関数を使います。
今回は援軍の備忘録を例に、サイト情報を抜き出す方法を記載します。
IMPORTXML関数の基本的な使い方
関数は以下のように記載します。
IMPORTXML(URL,Xpath)
URLは抜きだいしたい情報が存在するページのURL
Xpathは抜き出したい情報の置いてあるページ内の住所のようなものです。
例として、以下の記事のタイトルを取得してみましょう。
ページのURL:https://engun.co.jp/success-stories_rsa_title/
タイトル:【改善事例】レスポンシブ検索広告のタイトルを固定するとどうなるか?
この場合、以下のように記述します。
=IMPORTXML(“https://engun.co.jp/success-stories_rsa_title/”,”//title”)
※ページタイトルのXpathは「//title」となります。
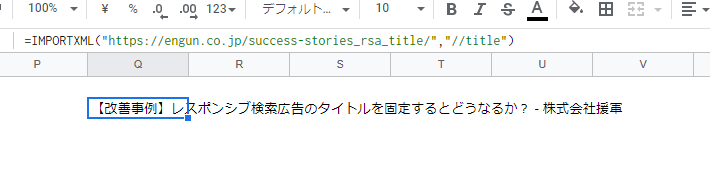
タイトルを正しく抜き出せました。
Xpathの取得方法
先程はページタイトルだったので、「//title」というXpathで抜き出せましたが、実際にはECなら商品の価格、不動産なら物件の住所や築年数など、様々な条件で抜き出したい場面があるかと思います。
そういった場面ごとに応じて、必要なXpathは変わってきます。
どんな場面においても共通して使えるXpathの取得方法を説明します。
ここでは主流なブラウザであるGoogleChromeを例に進めます。
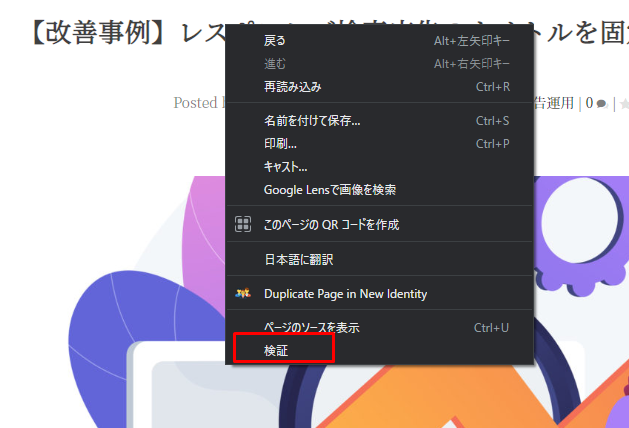
1)まずは、情報を取得したい箇所(今回は記事タイトルとします。)にカーソルを合わせ、右クリックを押します。
出てきたメニュー下部の「検証」をクリックします。
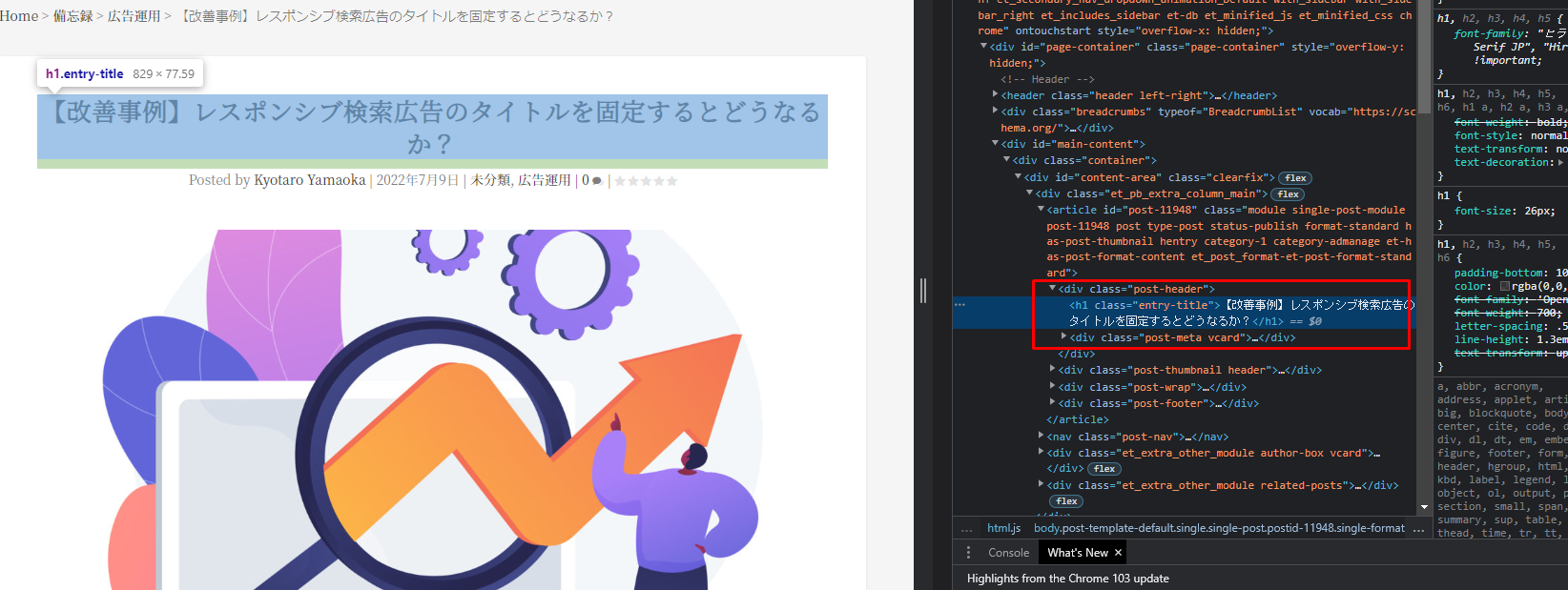
すると、画面右側にサイトのソースコード(HTML)が記載された画面が出てきます。
以下赤枠のように、今回カーソルを合わせた箇所に該当するコードが色付けされます。
2)その色付けされたコードの箇所にカーソルを合わせ、右クリックを押すと、メニューが出てきます。
ここで、「Copy>Copy Xpath」を選択します。
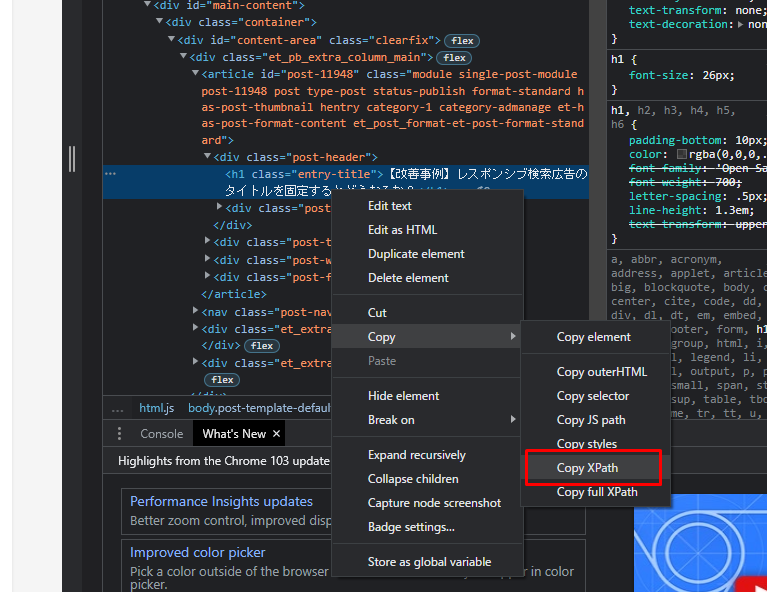
これでこの要素のXpathがコピーされたので、スプレッドシートに張り付けます。
今回は以下のようなXpathになっています。
//*[@id=”post-11948″]/div[1]/h1
3)このXpathに対して再びIMPORTXML関数を使用します。
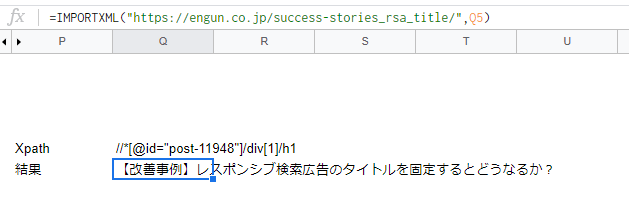
無事に記事タイトルを取得することが出来ました。
以上となります。意外と簡単です。
同様の方法で、記事のライター情報を抜き出してみます。
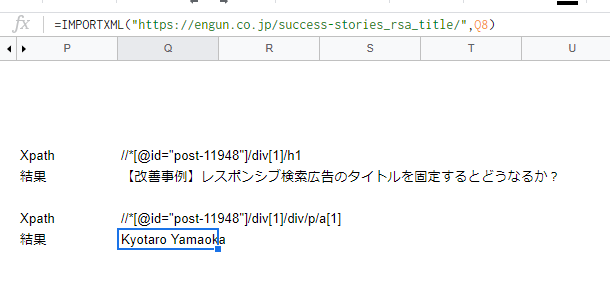
こちらも無事に取得することが出来ました。
このような方法で、サイトのあらゆる情報をXpathとIMPORTXML関数を使ってスプレッドシート上に抜き出すことが可能です。
今回は1URLだけで行いましたが、以下のようにすれば複数のURLに対して一気に情報を抜き出すことも可能です。
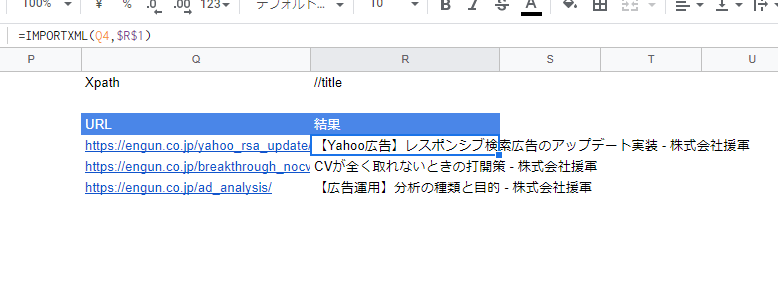
注意点
使いこなせれば非常に便利な方法ですが、一度に膨大な情報を一気に抽出するのはお勧めしません。
その理由は以下の2点です。
・結果の抽出に時間がかかる
・サイトに負荷がかかる
私の経験上、結果の抽出がある程度スピーディに行える基準値としては、一度に30~40個程度までにしておくのが良いかと思います。
また、大量に情報を取得しようとするとサイトに負荷がかかり、サイトの表示速度が遅くなったり、サーバーがダウンしてしまう恐れもあります。
サイトに負荷を掛けないように慎重にやりましょう。
また、サイトによってはこういった方法での情報の取得(スクレイピングと言います。)が禁止されている場合もありますので、注意しましょう。









{kind=link}